Editor's note: Mark Kaganovich is founder of SolveBio and a doctoral candidate in genetics at Stanford University. Follow him on Twitter @markkaganovich.
Much ink has been spilled on the huge leaps in communications, social networking, and commerce that have resulted from impressive gains in IT and processing power over the last 30 years. However, relatively little has been said about how computing power is about to impact our lives in the biggest way yet: Health. Two things are happening in parallel: technology to collect biological data is taking off and computing is becoming massively scalable. The combination of the two is about to revolutionize health care.
Understanding disease and how to treat it requires a deep knowledge of human biology and what goes wrong in diseased cells. Up until now this has meant that scientists do experiments, read papers, and go to seminars to get data to build models of both normal and diseased cell states. However, medical research is about to go through a tectonic shift made possible by new technological breakthroughs that have made data collection much more scalable. Large amounts of data combined with computers mean that researchers will have access to data beyond just what they can themselves collect or remember. A world with affordable massive data in the clinic and in the lab is on the horizon. This will mean exponentially faster medical progress.
{kind=link}
New technology is changing research
A major challenge thus far has been the difficulty in gaining access to clinical data. Observational studies have had limited success because collecting enough meaningful data has not been possible. For research to move faster human clinical data must be collected and integrated to yield actionable results, by universities, hospitals, and biotech companies.
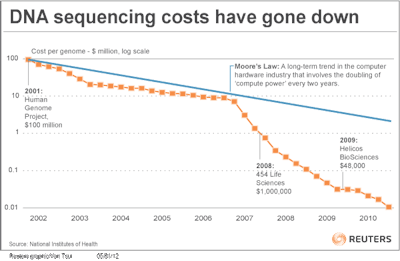
Developments in biotechnology over the last 10 years are painting a picture of how the new world of "Big Bio" might come into existence. Rapidly improving scale and accuracy of DNA sequencing has led to leaps in our understanding of genetics. This is just the beginning – sequencing technology is still very much in development. There are three publically traded companies, and about a dozen high profile startups/acquired startups whose entire business is the race for faster, cheaper, more accurate sequencing. At this point, clinical applications are usually limited to screens for known genetic markers of disease or drug response, but as the cost of data acquisition drops we will start to see companies and academics use unbiased observational correlations to generate meaningful hypotheses about the genetic causes of disease.
{kind=link}
Sequencing is one of many technologies experiencing a revolution in accuracy and scale. Progress is being made in imaging and identifying proteins, metabolites, and other small molecules in the body. The result is the opportunity to create pools of comprehensive data for patients and healthy people where researchers can integrate data and find patterns. We simply haven't had anything like this before. Patients can measure every feature, as the technology becomes cheaper: genome sequence, gene expression in every accessible tissue, chromatin state, small molecules and metabolites, indigenous microbes, pathogens, etc. These data pools can be created by anyone who has the consent of the patients: universities, hospitals, or companies. The resulting networks, the "data tornado", will be huge. This will be a huge amount of data and a huge opportunity to use statistical learning for medicine. It could also create the next engine of economic growth and improve peoples' lives. The question remains how will all this data be integrated. The missing piece of the puzzle is the parallel advancement we've seen in the past 6 years in cloud computing.
Correlation in the cloud
The cloud will make data integration possible, useful, and fast as new types of data appear. Data and algorithms can be distributed to people who specialize in different fields. The cloud can help create a value network where researchers, doctors, and entrepreneurs specializing in certain kinds of data gathering and interpretation can interface effectively and meaningfully. The true value of the data will begin to be unlocked as it is analyzed in the context of all the other available data, whether in public clouds or private, secure silos. This massively integrated analysis will speed the transition from bleeding edge experimentation to standards as solutions and data interpretations move from early-adopter stage to the good-enough stage where they will compete on ease-of-use, speed, and cost.
SolveBio, my startup, is working on making it better and easier to run large-scale analysis apps and data integration tools by taking advantage of bleeding edge cloud computing. The result will finally be literal exponential growth in medical knowledge in the sense that new medical discoveries will benefit further discovery. The results of research will create clinical demand that will be fed back into the data tornado for analysis.
A key area that is likely to be the first to benefit from massively distributed data integration technology is cancer research. At some point you will get cancer if you live long enough because cancer is a disease of genetic regulation going wrong. The thing that makes it complicated is that cancers result from many different things going wrong in different cells. For complex diseases, lumping cases together into a few linguistic terms doesn't reflect the biology: we have classifications like asthma, autism, diabetes, and lymphoma, but the reality is that each pathology is probably significantly different among individuals on dimensions that can be relevant to therapy. As Clay Christensen and colleagues point out in Innovator's Prescription, there used to be 2 types of "blood cancer" and now physicians classify 89 types of leukemias and lymphomas. The reality is probably that there are N types of lymphomas, where N is the number of people who have lymphoma.
Cancer research = Big Bio
Cancer is the ultimate Big Bio problem. Tumors may have millions of mutations and rearrangements as compared to normal tissue in the same individual, and cancer cells within the tumor itself may have different genomes. Most of the mutations may be uninformative "passengers" that come along for the ride, whereas many might be "drivers" that actually cause the unregulated cell proliferation that defines cancer. To distinguish between "drivers" and "passengers" very many cases and controls are needed to understand which mutations repeatedly appear in cancerous, but not normal cells.
Collecting comprehensive profiles of every tumor for every patient provides a dataset to build models that learn normal cellular function from cancerous deviations. Diagnostics and treatment companies/hospitals/physicians can then use the models to deliver therapy. If we imagine a world where every tumor is comprehensively profiled, it quickly becomes clear that not only will the data sets be very large but also involve different domains of expertise required for quality control, model building, and interpretation. Every cancer and person will be different based on their genome, proteome, metabolite and small molecule profiles, and features we have yet to discover. Stratifying by every possible relevant dimension to build the best models of effective drug targets and treatment regiments is a massive computational task. With current technology it takes a 16GB RAM desktop about 2 days to process gene expression data. If a biotech is analyzing a couple thousand patients, with 10 time points, and a few cancer samples each time, that quickly adds up to 570 years on the desktop. This is just gene expression profiling, and doesn't take into account the downstream data integration analysis to find informative correlations. Only a distributed computing platform can get the job done, and the cloud opens this work up to the masses.
We are catching a glimpse of how just DNA sequencing and computation can contribute to the transformation of oncology from the realm of Intuitive Medicine to Precision Medicine (to borrow from Clay Christensen, again). A major first step is to better target therapies based on genetics. It is estimated that only one-fourth of administered chemotherapy drugs have their intentional cytotoxic effect. Herceptin (Genentech) was the first cancer drug to actually come with a genetic test: it targets tumors specifically over-expressing one gene. Many more are in the pipeline, and Foundation Medicine is working on ways to better inform doctors and pharma companies as to how to target new drugs based on gene sequencing. Numedii is using genomic profiling to reposition drug compounds already approved by the FDA. Champions Oncology can graft your tumor onto a mouse and test drugs there.
Big Bio in Cancer research has game-changing implications for treatment and diagnosis. As other types of data are measured for cancer cells we will learn more and more from data integration. The cloud can seriously help treat cancers by allowing researchers, doctors, and engineers gather, interpret, and integrate data on unprecedented scales. As we begin to understand more precisely how individual cancers work, drug development ventures will have a much better sense of what to focus on, diagnostics companies will know what to look for, and patients will be treated by therapies that maximize effectiveness and minimize side effects – all based on actual data.
[image from Moneyball]
No hay comentarios:
Publicar un comentario